The mysterious maths at work in the Tour de France

 Getty Images
Getty ImagesIf you look at where previous winners of the world's most famous cycling race are from, a surprisingly common pattern emerges.
The Tour de France is without doubt the most famous cycling race in the world. Athletes from a range of different countries around the world are pitted against each other over a three-week race for the famous yellow jersey. Along with billions of others, I enjoy watching the spectacle of these almost superhuman athletes pushing themselves to the absolute limit in the beautiful French terrain.
Like many fans, I start the summer reading up on the approaching race. But recently I came across a graphic I had never seen before – the number of wins of the Tour by nation. What struck me was the smooth arc of the curve as it declined from left to right. In particular, I noticed that Belgium, the country ranked second in terms of wins with 18, had exactly half the 36 wins achieved by French riders . The country with the next highest number of Yellow jerseys, Spain, had exactly one third (12) the number of France's wins. Italy, the next nation on the list had just one more than a quarter (10) of the number of French victories.
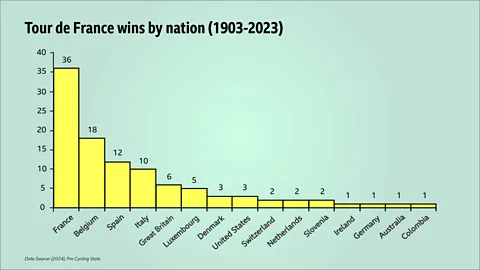
This reminded me very strongly of a mysterious and ubiquitous distribution to which many real world data sets seemingly conform. "Zipf's law" is probably best known to characterise the frequencies of words in a body of writing. In this context, the law states that, for a large enough text, when the words are lined up in order of decreasing frequency, they exhibit a special pattern. Specifically, the second-most-frequent word occurs roughly half as often as the most frequent. The third-most-frequent word occurs approximately one-third as often as the first, the fourth a quarter as often and so on – just as we saw with the Tour de France winners.
To put it to the test, when I analysed the word frequency of one of my own books, lo and behold, I found a startlingly good agreement with Zipf's law, which you can see in the graph below. The most common word I used in the book was "the" – 6,691 times. In second place came "of" with 3,330 occurrences – almost exactly half the number of times that "the" appears. The word "to" came next with 2,445 appearances, slightly over one-third the frequency of "the" – and so on. Incidentally, the words "life" and "mathematics" registered 64 times, while "death" occurred only 42 times, despite the title of the book being "The Maths of Life and Death".
Even when looking at the paragraph above, we can see that there are some extremely common words, such as "the", mixed with rarer words such as "startlingly" and "appearances". In a large enough text, while it is much less likely for any particular rare word such as "startlingly" to appear than any particular common word like "the", what Zipf's law is telling us is that there are far more rare words than there are common ones. Indeed Zipf's law suggests that these factors balance each other out, so that if we draw a word at random from a text it is just as likely to be one of the many rare words as it is to be one of the few common ones.
Zipf's law for word frequency in a large text is universal. It doesn't just hold for English, but seemingly for many other languages – even the artificial language, Esperanto. Fascinatingly, this almost magical relationship isn't simply limited to words in a text, as we saw with our Tour de France example. It has also been reported to have been found in extremely diverse scenarios, like the number of papers written by scientists, the population size of settlements, immune-related amino-acid sequence lengths and even the diameters of craters on the moon.
More like this:
• How coin tosses can lead to better decisions
Zipf's law is a special case of a more general rule called a power law. Power laws, in this context, suggest that one variable (the strength of the pull of Earth's gravity, for example) varies inversely with some other variable (the distance from the Earth's centre) raised to some mathematical "power". For gravity, the shorter the distance from the centre of the earth, the stronger the pull, while the larger the distance, the weaker the pull. Zipf's power law for words in a large text is a special case for which the "power", or "exponent", in the power law is one. This means that doubling one variable halves the other and that tripling the first decreases the second by one third and so on.
For a general power law, however, this is not usually the case. The "inverse square law" of gravitation, for example, follows a power law whose exponent (or power) is two. If you were to move twice as far away from the centre of the earth compared to where you are currently sitting, then the force you would experience at your new position would be four (two squared) times as weak as it is where you are now. If you move three times as far away, the force will be nine (three squared) times as weak and so on.
Power laws have been found to describe a wide range of naturally generated data sets, from the variation of species diversity with habitat area to the frequency of the number of tornadoes per day in the United States and even how the number of artists varies with the average price of their work. Analysing data on wars from 1809 to 1949, Lewis Richardson found that the frequency of fatal conflicts varied with the number of people killed according to a power law with exponent ½. Wars in which one million people died were found to be 10 times less likely than wars in which 10,000 people died and 100 times less likely than conflicts in which 100 people died. Perhaps one of the most important power laws ever discovered was published by Charles Richter and Beno Gutenberg in 1956, which describes how the frequency of earthquakes varies with their magnitude.
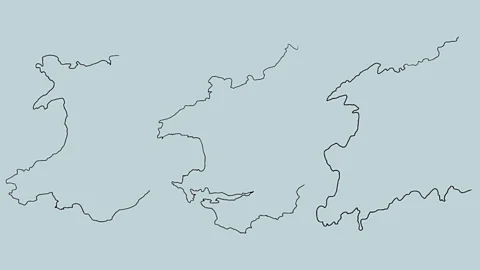
It's clear that power laws are important for describing a wide range of real-world phenomena, but why do they appear to be so ubiquitous? Mathematically it can be shown that power laws will arise when systems exhibit scale invariance or self-similarity. Systems exhibiting these related properties look the same (or roughly the same) when we zoom in or out on them. Fractal coastlines are an oft-cited example of self-similarity – it's hard to tell, given the outline of a piece of coast, exactly the scale at which you are viewing (as you can see in outlines of the Welsh coastline in the image below). As you zoom in, the structures of the coastline remain similar. Many real world phenomena, from networks like the internet, to naturally occurring physical phenomena like snowflakes, and biological structures like ferns, exhibit self-similar properties. Power laws capture this self-similar property mathematically.
Perhaps the most convincing explanation for Zipf's law itself argues that there are latent or unobserved variables which work to mix together multiple components that by themselves do not obey Zipf's law, but when combined do. In the context of word-frequency, for example, the components are the different parts of speech (eg adjectives, conjunctions, nouns, prepositions, verbs etc). For example, because they are general and are used in sentences irrespective of the context, there are very few different conjunctions (eg "and", "because") each of which is relatively common. Contrastingly, although there are far more nouns (eg "speech", "law" etc) each one of them can only be used in relatively few specific contexts that involve an exact thing, making each one comparatively rare. Individually these components do not obey Zipf's law, but when these parts of speech are mixed together with others to form language they do.
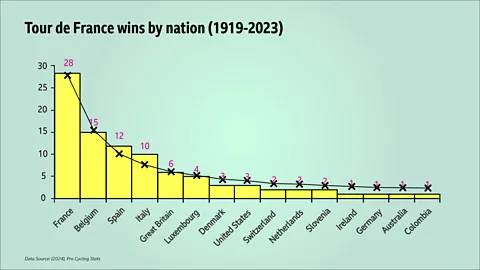
The Tour de France is also not the only sporting context in which Zipf's law has been found to hold. It occurs in situations such as Olympic medal tables and snooker prize money. But exactly why Zipf's law should hold for Tour de France winners is not clear. In fact, as you might expect, when you plot Zipf's distribution on top of the real data, the agreement is not perfect. The European nations, France and its close neighbours Belgium, Spain and Italy, who have won the Tour the most, are over-represented. In some senses this is unsurprising. The make-up of early Tours de France were dominated by the French and later by their neighbours. In the first edition of the Tour in 1903, for example, 49 of the 60 cyclists who entered were French. If you remove all the winners before the First World War, we can find an improved agreement with Zipf's law (see the graph below).
 BBC/Kit Yates
BBC/Kit YatesGiven there has been no French winner of their most famous sporting event since 1985, some of the underrepresented nations have had a chance to take their place in the distribution.
But what does that mean for this year's race? Sadly, Zipf's law speaks only in generalities and doesn't offer us answers to such specific questions. Whatever happens though, even as the memories of their last win fade from the public's consciousness it's going to take many more years for the evidence of France's early domination of the Tour to fade from the data.
* Kit Yates is in the Director of the Centre for Mathematical Biology at the University of Bath and the author of The Maths of Life and Death, and How to Expect the Unexpected.
--
If you liked this story, sign up for The Essential List newsletter – a handpicked selection of features, videos and can't-miss news, delivered to your inbox twice a week.